如何终结代码审查
人类编写的代码在 2025 年消亡。代码审查将在 2026 年消亡。
💡 软件工程专家导读:核心洞察与反常识提炼
- 代码审查(Code Review)已死:即使在 AI 出现前,人类审查速度也早跟不上代码产出。AI 时代代码量指数级暴增,试图用 AI 审查 AI 代码只是在拖延时间,并没有解决根本问题。
- 审查对象发生根本转移(从“代码”到“意图”):未来的核心不再是逐行阅读 Diff,而是审查规范(Specs)、约束和验收标准。规范将取代代码,成为事实的唯一来源(Source of Truth)。
- BDD(行为驱动开发)的真正春天:过去写规范被视为额外负担,但在 AI 原生开发中,人类只负责定义“正确”的边界和业务逻辑,AI 负责将其翻译成代码。
- 构建“对抗性”与“分层”的机器信任:不要指望 LLM 自我验证。应引入:1) 多智能体竞争(生成多个方案择优);2) 确定性护栏(不可商量的客观测试契约);3) 对抗性验证(红蓝对抗:一个智能体写代码,另一个专找漏洞,相互物理隔离)。
- 终极反常识结论:如果智能体能完美地处理代码并通过确定性测试,人类能不能读懂这些代码,根本不重要。未来的工作流是“快速交付、全面观测、即时回滚”,而不是“缓慢审查、依然漏掉 bug、在生产环境中调试”。
当人类以人类的速度编写代码时,人类就已经无法跟上代码审查的步伐了。我交谈过的每一个工程组织都有同样的不可告人的秘密:PR 搁置数天、走过场式的批准,以及审查员匆匆略读 500 行的代码差异(diff),因为他们还有自己的工作要做。
我们告诉自己这是一道质量关,但几十年来,团队在没有逐行审查的情况下也一直在发布软件。一位资深工程师告诉我,直到 2012-2014 年左右,代码审查才开始普及,只是我们中记得这件事的人不够多了。
即使有审查,问题也会发生。我们学会了构建能够处理故障的系统,因为我们接受了仅仅靠审查是不够的。这体现在功能标志(feature flags)、灰度发布(rollouts)和即时回滚(instant rollbacks)等方面。
我们必须放弃阅读所有代码
根据来自 1,255 个团队的 10,000 多名开发人员的数据,AI 采用率高的团队完成的任务增加了 21%,合并的拉取请求(PR)增加了 98%,但 PR 审查时间却增加了 91%。
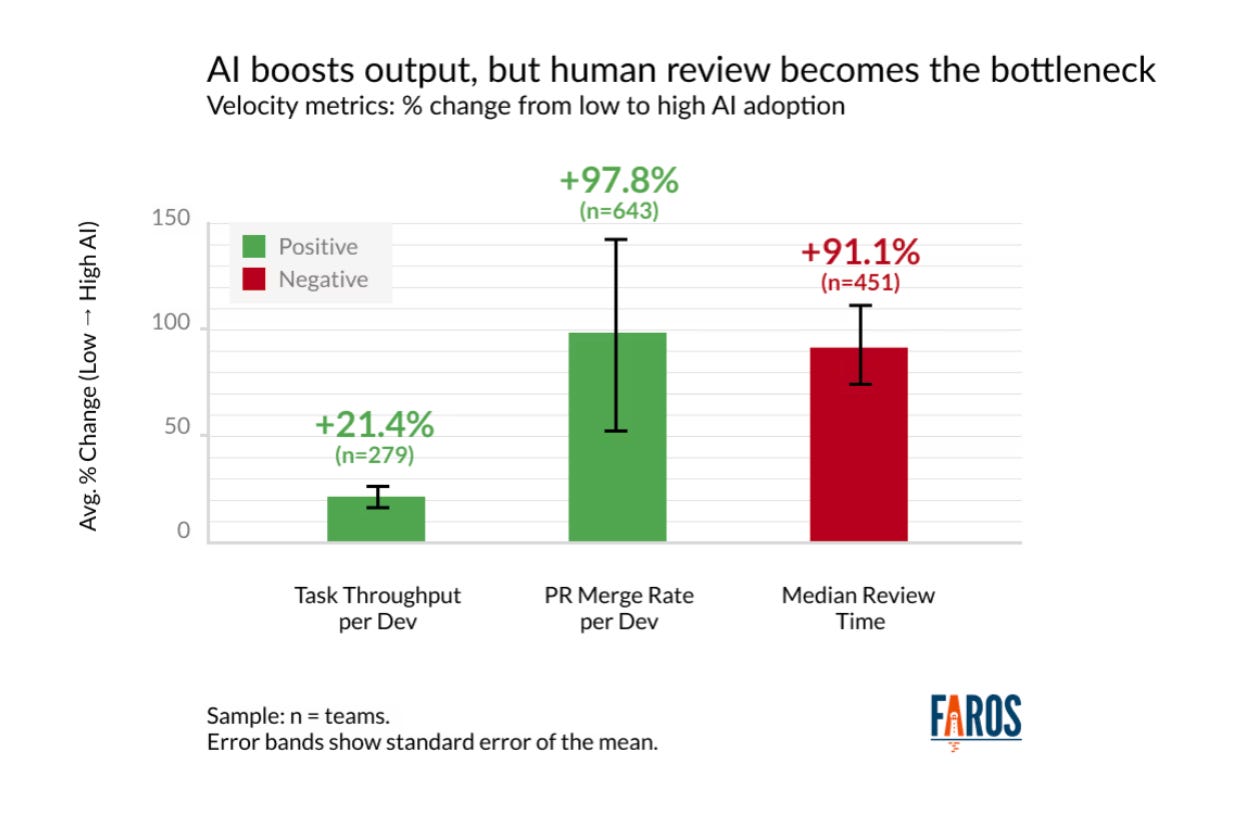
有两件事正在呈指数级增长:变更的数量和变更的规模。我们无法消化这么多代码。就是这样。最重要的是,开发人员不断表示,审查 AI 生成的代码比审查同事编写的代码需要更多的精力。团队生成了更多的代码,然后花更多的时间来审查它们。
我们不可能通过手动代码审查来赢得这场战斗。代码审查是一个历史悠久的审批关卡,它已经不再符合当前工作的形态。
AI 代码审查仍然是审查
AI 代码审查工具只是在为我们争取时间。如果 AI 编写代码而 AI 进行审查,为什么我们还需要一个漂亮的审查 UI 来显示它呢?尽管 AI 代码审查非常有价值,但它们将向开发周期的左侧(早期阶段)移动。没有理由在审查周期之间浪费 CI 资源和管理版本控制。
在人类编写代码且需要新视角(fresh eyes)的时代,PR 后的审查是有意义的。但当智能体(agents)编写代码时,“新视角”只是另一个具有同样盲点的智能体。这里的价值在于迭代循环,而不是作为一个审批关卡。
我们从经验中知道智能体并不总是可靠的,而且人类很容易产生这种想法:我曾经抓住过 AI 做蠢事;因此,我必须经常检查它。当手动验证可行时,这种本能是有意义的。但在目前的规模下,它不再可行。而且情况只会变得更糟。
从审查代码到审查意图
答案是将人类检查点向上游移动。如果想到不审查代码似乎很可怕,请允许我提醒你,在软件开发中检查点以前也移动过。我们从瀑布式的签核转变为持续集成。我们完全可以再次移动它们。
规范驱动(Spec-driven)的开发正成为与 AI 协同工作的主要方式。人类应该审查规范、计划、约束和验收标准——而不是 500 行的差异代码。
在这种新范式中,规范成为事实的唯一来源。代码成为规范的副产物。你不需要审查代码。你需要审查步骤。你需要审查验证规则。你需要审查代码必须履行的契约。
人类在环(Human-in-the-loop)的批准将从“你写对了吗?”转变为“我们是否在正确的约束条件下解决正确的问题?”最宝贵的人类判断是在生成第一行代码之前进行的,而不是在之后。
通过分层建立信任
在我们停止阅读代码之前,我们需要感到多么自如?
以规则形式表现:
代码 不得由人类 编写
代码 不得由人类 审查
LLM 并不擅长遵循命令。它们会偏离。很频繁。而且它们在自我验证方面并不可靠——它们会自信地告诉你代码运行正常,而此时它可能正处于崩溃状态。解决办法不是让 LLM 去验证。而是让它写一个能够验证的脚本。我们需要实现从人为评判到客观产物的转变。
信任是分层的。这就是瑞士奶酪模型:没有单一的关卡能抓住所有问题。你叠加不完美的过滤器,直到漏洞不再对齐。那么,我们还能在哪里设置审批关卡呢?
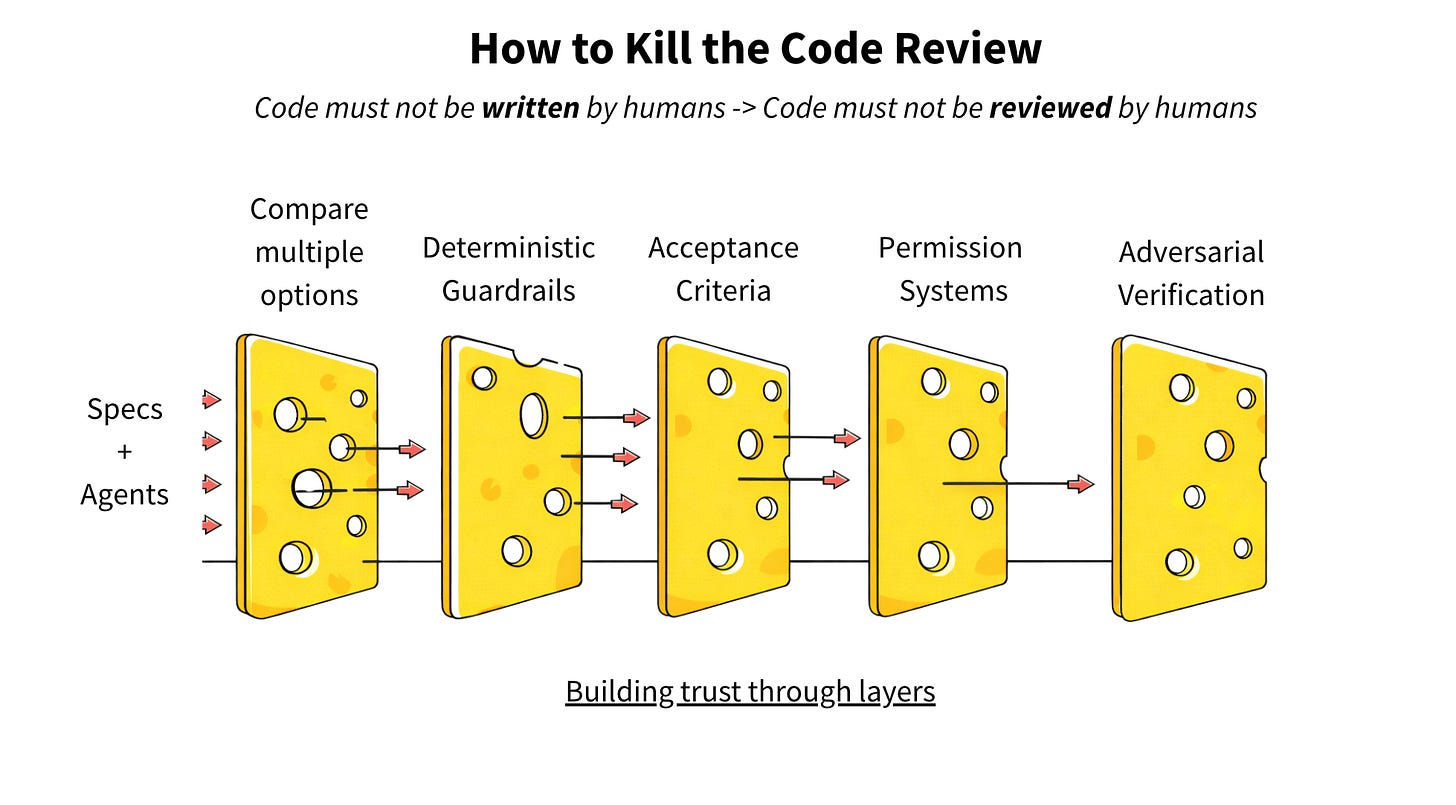
第 1 层:比较多个选项
不要只要求一个智能体一次性把事情做对,而是要求三个智能体用不同的方法尝试,并挑选出最好的结果。让它们竞争。在软件工程的历史上,获得选择权的成本目前是最低的。
这种选择也不一定是手动的。你可以根据哪个输出通过了最多的验证步骤、哪个产生了最小的代码差异、哪个没有引入新的依赖项来对输出进行排序。竞争会产生一种你在单次尝试中无法获得的信号。
第 2 层:确定性护栏
应该有一种确定性的方法来验证工作。测试、类型检查、契约验证 - 这些东西没有主观意见,只有事实。
不要问 LLM“这个有效吗?”,你需要定义产生一系列通过/失败产物的验证步骤。智能体无法与失败的测试讨价还价。它要么符合规范,要么不符合。
这些护栏本身也可以被定义为不同的层次:
- 编码指南 - 这些可以是自定义的代码检查工具(linters)
- 组织范围内的不变量 - 不可妥协的底线,例如不包含硬编码的凭据、API 密钥或令牌
- 领域契约 - 针对特定框架、服务或代码库某部分的契约,例如支付领域:所有金额均使用 Money 类型
- 验收标准 - 针对特定任务的要求
验证步骤应该在编写代码之前定义,而不是在编写之后发明出来以确认已经存在的内容。如果智能体既编写代码又编写测试,你只是转移了问题——现在你是在信任智能体会去测试正确的东西。验证标准需要来源于规范,而不是代码实现。
第 3 层:由人类定义验收标准
那么人类在哪里增加价值呢?在上游,定义成功是什么样的。
这正是行为驱动开发(BDD)重新变得相关的地方。BDD 一直是个好主意——用自然语言编写描述预期行为的规范,然后将这些规范自动化为测试。但它从未完全流行起来,因为当你本来就要编写代码时,编写规范感觉像是额外的工作。
有了智能体,情况发生了反转。规范不再是额外的工作;它是主要的产物。你写下:
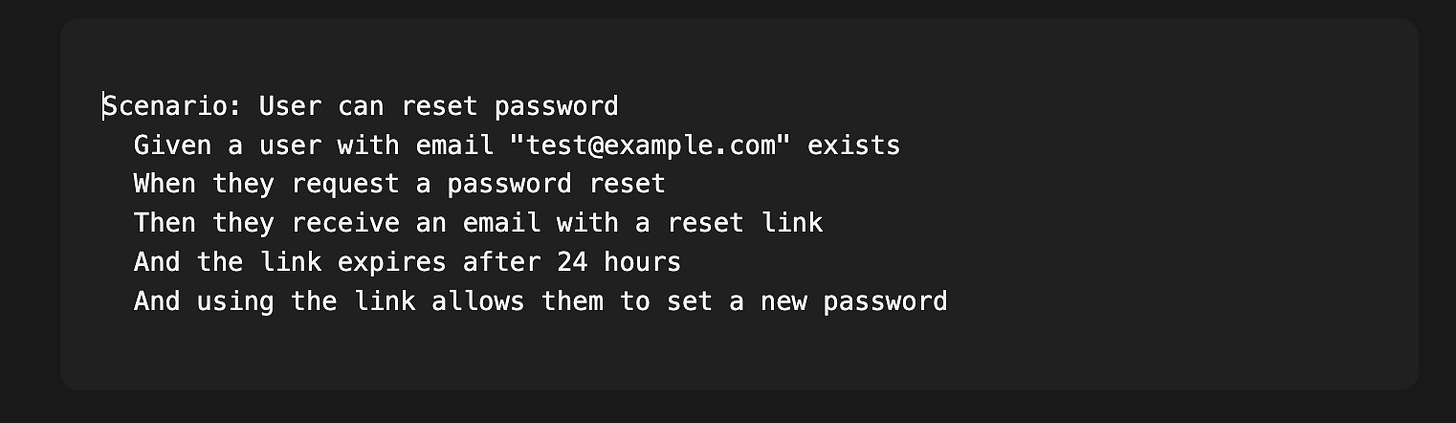
智能体负责实现。BDD 框架负责验证。除非出现问题,否则你永远不需要阅读代码实现。
这就是人类在做自己擅长的事情:定义“正确”的含义,将业务逻辑和边缘情况编码,思考可能会出什么问题。智能体处理从意图到代码的转化。BDD 规范成为了你的验证层——它是确定性的、自动化的,并在写下第一行代码之前就已经定义好了。
由人类编写的验收标准,由机器来验证。这才是真正重要的关卡。
第 4 层:作为架构的权限系统
这个智能体能触碰什么?什么情况需要上报升级?这些都成了架构决策,而不是事后才想到的补充。
大多数智能体框架将权限视为一种全有或全无的设置。智能体要么拥有 shell 访问权限,要么没有。但细粒度很重要。一个修复工具函数中 bug 的智能体不需要访问你的基础设施配置。一个编写测试的智能体不需要修改 CI 管道。
权限范围应尽可能窄,同时仍能让智能体做有用的工作。如果任务是“修复 utils/dates.py 中的日期解析错误”,那么智能体的文件系统访问权限应仅限于该文件及其测试文件。不能是整个代码库。不能是“src/ 和 tests/”。只有对于这项任务相关的文件。
上报升级触发器同样重要。某些模式——触及认证逻辑、修改数据库模式、添加新依赖项——应该自动标记给人类进行审查,无论智能体有多自信。
第 5 层:对抗性验证
职责分离:一个智能体负责工作,另一个负责验证。它们互不信任,这正是关键所在。
这是一个古老的模式——这就是为什么你的 QA 团队不应该向你的工程经理汇报,以及为什么编写代码的人不应该是唯一一个审查它的人。
有了智能体,你可以在架构上强制执行这一点。编码智能体不知道验证智能体将检查什么。验证智能体没有修改代码以简化自己工作的能力。它们在设计上就是对抗性的。
你可以更进一步:第三个智能体试图破坏第一个智能体构建的东西,特别是针对边缘情况和故障模式。红队、蓝队——但它们是自动化的,并且在每次代码变更时运行。
结论:“好代码”的标准正在改变
智能体系统的动机很简单:给定一个任务,我能完成它吗?我能让给我任务的人满意吗?智能体的成功从不是天然由长期的准确性或业务需求驱动的。
我们的工作就是把这些要求在约束条件中进行编码。
对于由智能体生成并由智能体阅读的代码来说,什么是“好代码”将变得更加标准化。对于一个新的代码库,你需要提供的指导将会减少,因为默认设置将更加一致。
未来在于快速交付、全面观察、更快速地回滚。
而不是:缓慢审查,依然漏掉 bug,在生产环境中调试。
我们无法在阅读量上胜过机器。我们需要在思考上胜过它们——在真正重要的决策上游。
归根结底,如果智能体可以很好地处理代码,我们能不能读懂它又有什么关系呢?
本文作者:Ankit Jain 是 Aviator 的创始人兼 CEO,他正在为 AI 原生工程团队构建基础设施。Aviator 的平台帮助现代组织提高 AI 采用率,同时保持高水平的工程标准。